Yes, the title is clickbaity, but stick around, this is going to be interesting.
I’ve been excited about a new way of developing software for a while now and with this post I want to introduce what’s this all excitement about.
I’m going to talk about abstractions, business logic and graphs, and what I believe can be the next step in the software development.
Kubernetes, memory management and abstractions
Abstractions are particularly useful to our limited brains, it enables us to deal with complex concepts and information. I’m not going to dig further in the theory of abstractions, but instead offer a practical example of what I’m talking about: memory management in modern programming languages.
If a today’s typical web developer doesn’t need to directly deal with memory management, it is because any modern high-level programming language have an out-of-box reliable abstraction around it, one that takes away all the complexity and the hassle of dealing with such details. Of course, this was primarily enabled by cheaper and cheaper modern memory modules but still, dealing with it thorugh a reliable abstraction increased software developers productivity by at least tenfold.
We can mention a similar story when you compare lower and higher level programming languages. You probably use the latter to develop most of your non-technical user-facing software.
Another example of a recently new abstraction: In 2014, Kubernetes came to existence as a mere container-orchestration system. It is not an understatement to say it became much bigger than that: either you like it or not, Kubernetes changed the way companies and developers deploy complex applications in a multi-node environment – it became a platform and a full ecosystem.
By creating new primitives like deployments, services and jobs, which can run in a normalized environment, we can say that Kubernetes created a reliable abstraction around services orchestration and monitoring, allowing developers to easily spawn, monitor, maintain and scale any software application.
So, it is natural to wonder: what is the next level of abstraction we are going to have that is going to increase the productivity baseline of our industry?
Business logic
If you work in a business facing application, you are used to the term “business logic”, but what exactly is it?
Wikipedia defines it as:
In computer software, business logic or domain logic is the part of the program that encodes the real-world business rules that determine how data can be created, stored, and changed.
Business logic in our industry means the way a software solves a real-world problem. And I really like the encode word in this definition, because that’s exactly what happens. The business logic is encoded as the code you write to make it work.
An practical and common example of a business logic definition can be:
As a visitor, I want to sign up with my Facebook account
We can say that this phrase defines a small unit of a business logic, in a User Story fake-Gherkin form. For an experienced developer, this is enough to develop a piece of software. But from that simple statement, a lot of implementation details needs to be figured out. Decision needs to be made. For example:
- Where does the authenticated user entity should be persisted? What are the persistence-related constraints and rules that should be implemented to assure data consistency?
- What programming language to use? Which web framework? Which libraries to connect with Facebook account? What should be used from its Facebook account?
These are just a few questions, during the implementation much more details arise. Most of those decisions will be taken based on the team’s or the assigned developer heuristics.
The business logic isn’t that phrase, it is the implementation. This phrase is just a projection. The code that gets executed in the server, that’s what is valuable. That phrase per se doesn’t allow the product’s user to actually sign in with their FB account. You need someone, usually a team, to write the code, deploy it to a server and create the correct configuration - integrating perfectly with FB’s API and doing all the required persistences.
Looks similar but the first definition is a business logic from mind product, the latter is the emergent functionality of the code.
The business logic emerges from the code written, the code that exposes and consumes multiple internal/external APIs in a very coordinated way, along persistence layers.
A company rarely have the business logic described apart from the technical implementation, if so, it’s in a loose documentation form: like Google Docs documentation, JIRA issues and user stories, like the one above. The problem is: loose business logic documentations, when they exist, are usually home of a lot of polysemies, which isn’t that helpful for such deterministic environment that software development is. And even if you don’t bother about dubious logic statements, it’s hard to keep in sync documentation with the code implementation.
The alternative way you can figure it out what’s a product’s business logic is by looking at its APIs and its persistence layers; Data entities and relationships between them. You need to look at the code.
As you can see commonly in the industry, you require a lot of people constantly working in sync so your implementation follows the business logic with more precision. And often the business logic is sparse and vague, leaving to the developer to figure out at implementation time, creating a great need for communication.
To make things worse, a big enough application gets many changes over its life, from multiple people and teams. Those changes adds more business logic, updates existent ones and sometimes even remove them. And it’s usually here the origin of most of the issues: conceptual integrity is corrupted or lost, technical debt increases due to lack of business logic clarity, the actual business logic is harder to grasp for future developers/product owners.
How can we avoid our applications to become a spaghetti of business logic, where we are not sure if everything makes sense? How can we declare our business logic in such a way that it remains connected with the actual code that gets executed in the server?
What if your declaration of business logic, like the Facebook Account example, can be a first class citizen in this process?
Business logic first, implementation follows
UML was an attempt of solving this issue, but it was considered a silver bullet and many tried to design entire aspects of an application with it. We all know that there are no silver bullets.
We don’t need to express all layers of abstractions in an application to solve the business logic issue. We only need a way of expressing the business logic, and this expression needs to be attached to the actual implementation somehow. Maybe through a language, not a programming, but a declarative one?
What if I told you that such language exists for couple of years now, and many are using it with some success? One language that allows declaration of business logic by just declaring your APIs, data entities and relationships: it is the GraphQL’s SDL.
GraphQL is a data query language and specification developed initially and internally by Facebook. Although it was born as an alternative to REST application interfaces, the small paradigm shift of considering your entities as a graph is powerful. Graphs are the most minimal structure for relational data we have, so we basically can represent every application, including external services, as part of just one graph.
Apollo, a company that provides GraphQL solutions, released the Principled GraphQL website which brings a really similar vision. Imagine your entire company being represented by a well-defined graph – the possibilities are endless.
Not only every new user story proposed by the product team could be modelled and defined as part of the graph, but the implementation constraints are already on it, and more importantly, could be validated at every change in the graph – especially if we have a typed graph.

An user story would be represented by schema definitions to be used in the graph. This is just a theoretical example.
Another advantage of this approach is that it happens in a simple enough language to allow non-developers to express the business logic without falling in the complexities of the implementation.
From the SDL, you already have the mutations and queries interfaces you must implement, as well the mutations and queries available for front-end development –– web and mobile applications.
SDL-first or code-first?
SDL-first is a model-driven development, where you define your schema first and later on you implement all the resolvers.
There are valid different opinions in the GraphQL community about SDL-first development, pointing out many current limitations when following this approach. They’re surely valid points, but I still believe that defining your entities and relationship first is a much better way of developing software.
It enables product owners, developers and interface designers to work around a well-defined logic. The graph makes sure all product roles are speaking about the same thing in regard of business logic - allowing a much more accessible Ubiquitous Language.
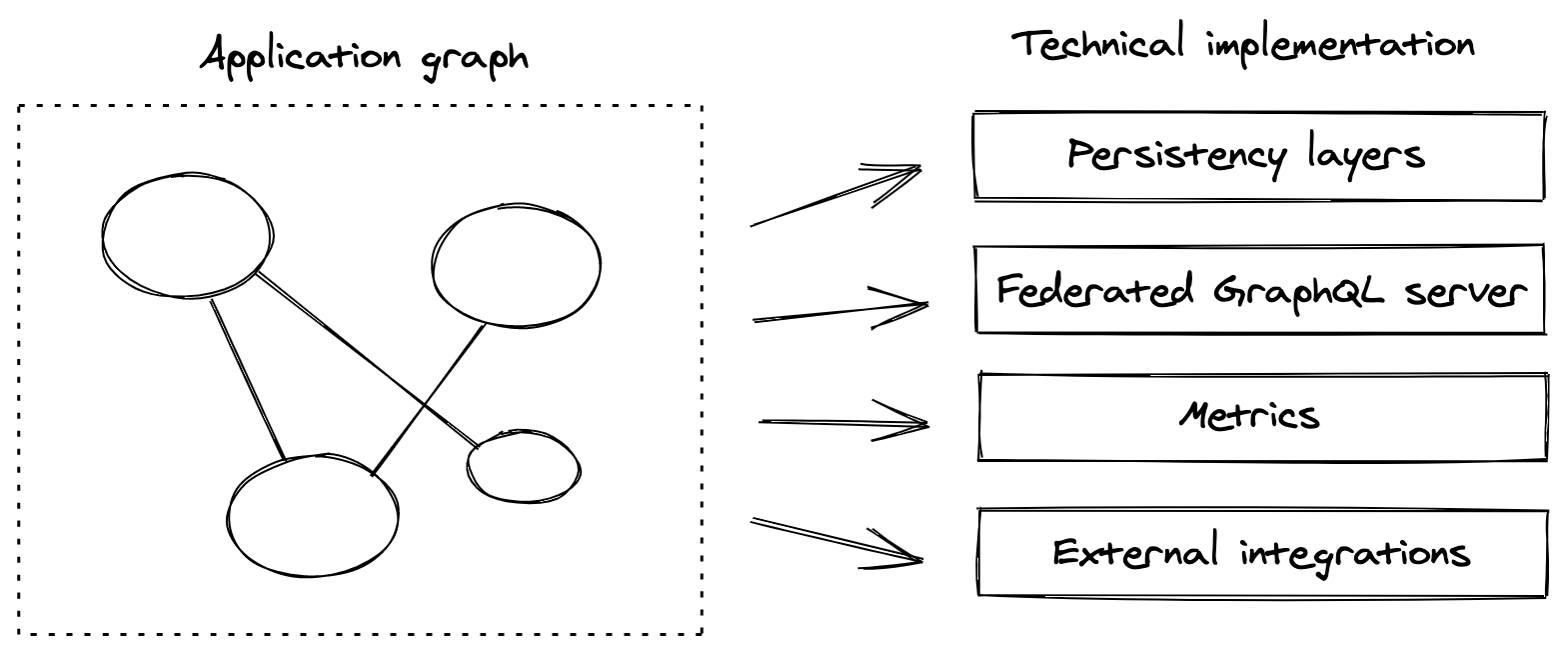
The implementation comes after the entities and interface declaration.
Of course, a deeper paradigm shift is required in how we develop software today to make this possible – and that will only be possible with better tooling. We already have very interesting tools available today, but in my opinion we still miss the one that lays down the process of developing software in a graph-first fashion: an integrated development environment.
Imagine a multidimensional graph-oriented IDE, where you can create and manage not only user stories, but its resulting graph definitions/changes, including external service integrations. In another dimension, back-end developers can define and code their own implementation-specific abstractions, connected by the requirements of the business logic (the first dimension). And in a third dimension, front-end developers and designers can work together on visual interfaces that allows interactions with the defined graph: already with the whole API at hand.
On this ultimate integrated development environment, we would have less human-prone errors and communication-related noise, increasing the productivity in orders of magnitude. It’s the missing linking between the loose business logic definition and the actual implementation.
The goal is not to recreate a UML alternative and have a silver bullet. The goal is to create an abstraction that connects business logic definition and the implementation of it, for our common use case of fast evolving software application.
Martin Fowler already wrote about this a decade ago, in his ProjectionalEditing, ModelDrivenArchitecture and other sublinked posts I highly recommend you to read.
The difference is that now I believe we have the tools to glue together to make it happen, and this can be the birth of a old-new direction to a faster, more consistent and more productive process of developing software.
–
Some references in case you want to take a deep dive on this:
- Principled GraphQL
- OneGraph
- Prisma Migrate: change your persistency structured based in your schema definition
- Hasura: expose database and services using GraphQL
- GraphCool (discontinued, but an interesting OSS BaaS)
- Postgraphile: instant GraphQL API generation from a PostgreSQL database
- Apollo Federation: declare one graph, implement it in multiple services
- These two posts in HN: